
August 2011, Vol. 238 No. 8
Features
Toward Better Pipeline Data Governance
“If you can’t describe what you are doing as a process, you don’t know what you’re doing.”
– W. Edwards Deming
On April 18 at the National Pipeline Safety Forum, National Transportation Safety Board (NTSB) Chairman Debbie Hersman posed the following question to a panel of industry representatives:
“Unfortunately in the San Bruno accident, we found that the company’s underlying records were not accurate… My question is that if your many efforts to improve safety are predicated on identifying risk, and if your baseline understanding of your infrastructure is not accurate, how confident are you that your risks are being assessed appropriately?”
In the previous installment we concentrated on the limitations of our data; in the final installment we’ll discuss the limitations of our pipeline risk models. For now, let’s examine what we can do to improve the overall quality of our data, and ultimately, reassure Hersman.
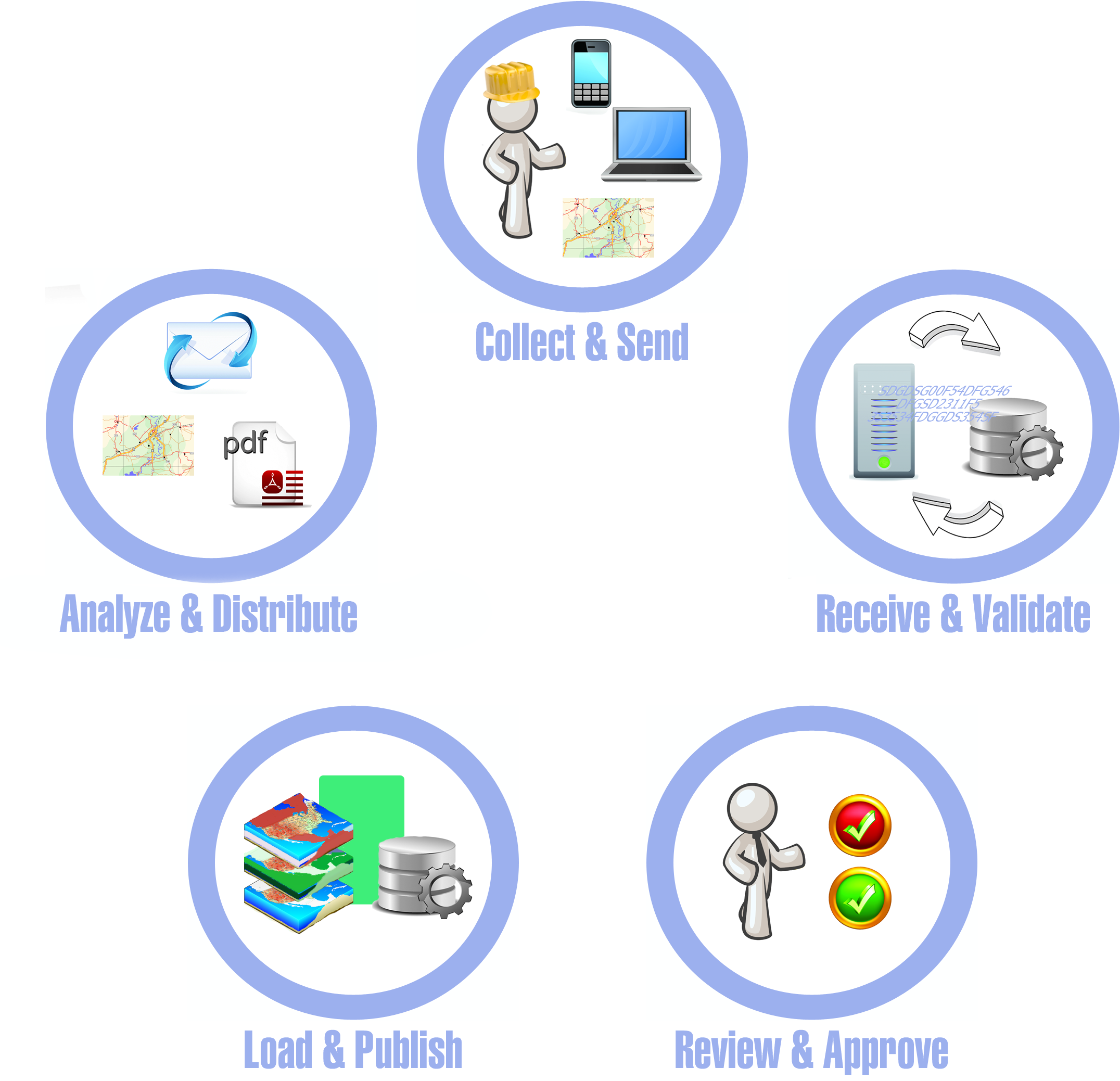
In the wake of the NTSB’s Jan. 3 urgent pipeline safety recommendations, many operators are scrambling to validate and verify the information in their pipeline databases. Many, if queried, would admit this is not their first round of data clean up. Some operators have been through multiple rounds of data clean up in recent years. It’s clear something’s amiss with the processes we use to populate our pipeline database systems. Consider the following generalized pipeline data lifecycle:
Historically, most operators have concentrated on Collect & Send (or simply Convert), Load & Publish, and Analyze & Distribute. Short shrift has been given to Receive & Validate and Review & Approve. Processes used are, in many cases, poorly documented and non-uniform. As a result, pipeline database errors are all too common, regulators are agitated, and operators are frenetically attempting to correct their pipeline database errors. However, correcting bad data after it enters your database is terribly inefficient.
If we think of data as a manufactured product, it’s reasonable to infer that data defects (errors and omissions) stem from deficiencies in our data manufacturing processes. Fortunately, decades of process management literature from the manufacturing sector is available to guide our data improvement quest. There are three prominent schools of manufacturing process management: 1) Six Sigma, 2) Lean Manufacturing, and 3) Theory of Constraints. They may be broadly summarized as follows:
• Six Sigma focuses on process improvement through defect reduction and process uniformity
• Lean Manufacturing focuses on process improvement through elimination of waste
• Theory of Constraints (TOC) focuses on process improvement through maximization of throughput (or, more appropriately to our discussion, minimization of data cycle time)
While the three schools differ in approach and emphasis, all concentrate on defect prevention. A note on Six Sigma – the name derives from the level of error deemed minimally acceptable in a modern manufacturing process. Assuming a Gaussian distribution in outcomes from a given manufacturing process, only outputs more than six standard deviations away from the mean result in a defect. That’s a defect rate of only 0.00034%, or 3.4 defects per million. Imagine if we could achieve a similar level of confidence in our pipeline data.
In pipeline data governance, our most damaging wastes are data defects and long cycle times. In some cases, data collected in the field takes months or even years to make its way into the database and thence to maps or alignment sheets. Data management practitioners are often overwhelmed; data errors creep in, and timely data distribution lags. The field technician ends up viewing the pipeline database as a black hole; data enter, but never escapes. Fortunately, three simple process management lessons can help mitigate our ailing data manufacturing processes.
Six Sigma teaches that if you don’t establish measurements for your processes, then you really can’t know very much about them. So the first lesson is to define measurements. Two forms of measurement are critical: 1) those that track cycle time, and 2) those that monitor defects. Cycle time measures are the yardstick for process efficiency. The most critical measure of cycle time is how long it takes for data captured in the field to make it back out to the field (e.g., in updated maps or alignment sheets). Identification and characterization of defects is of paramount importance, because until you understand a defect’s root cause, you can’t correct the process that produces it.
The second lesson combines Lean and Six Sigma concepts. From Six Sigma, all processes should incorporate fail-safe steps (or poka-yokes) designed to detect defects and stop the process before the defect is incorporated in the output. According to Lean, these fail-safe steps should be automated; when a fail-safe is triggered, processing should automatically halt and human intervention be initiated. Lean calls this “autonomation.”
Assume we’re collecting casing vent locations. Every casing vent should be in close proximity to both the pipeline centerline and a casing end, and casings should be in close proximity to a road or rail crossing. These types of “spatial context” fail-safes are simple to automate. The idea is to detect and correct defects before they enter your pipeline database. It’s far less expensive to correct data defects at, or close to, the point of collection, than it is to ferret out and correct data long (in some cases decades) after the fact. An ounce of prevention is worth a pound of cure.
The third lesson comes from TOC. A cursory examination of most as-is data management infrastructures reveals a target-rich environment for process improvement. The trick is prioritization. Following the precepts of TOC, process constraints should be addressed in priority order; the constraint that most impacts cycle time should be tackled first. Naturally, if you have appropriate process measurements, critical constraints tend to reveal themselves.
Most of this best lends itself to ongoing data collection and processing. However, much is applicable to validation, verification and correction of existing historical data. It’s never too late to improve your pipeline data governance processes.

Comments